
字节跳动蜘蛛Bytespider每日过分抓取我们的网站内容,公然不遵守robots协议,致使服务器高负载状态,下面就教大家如何设置Nginx。
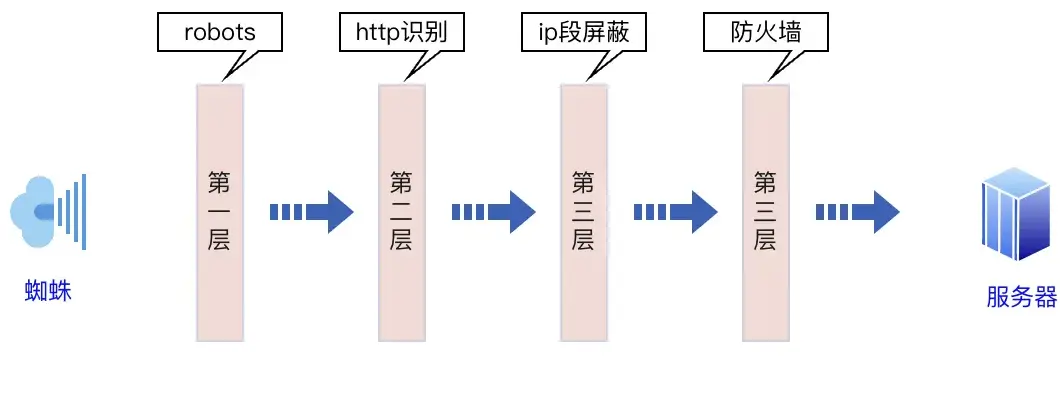

如上图所示,第一种对于不遵守robots协议无效;第二种亲测非常有效;第三种容易误伤;第四种系统版本不一定有效。
本次只讲第二种,步骤如下:
① 打开宝塔面板,点击网站 → 设置 → 配置文件;
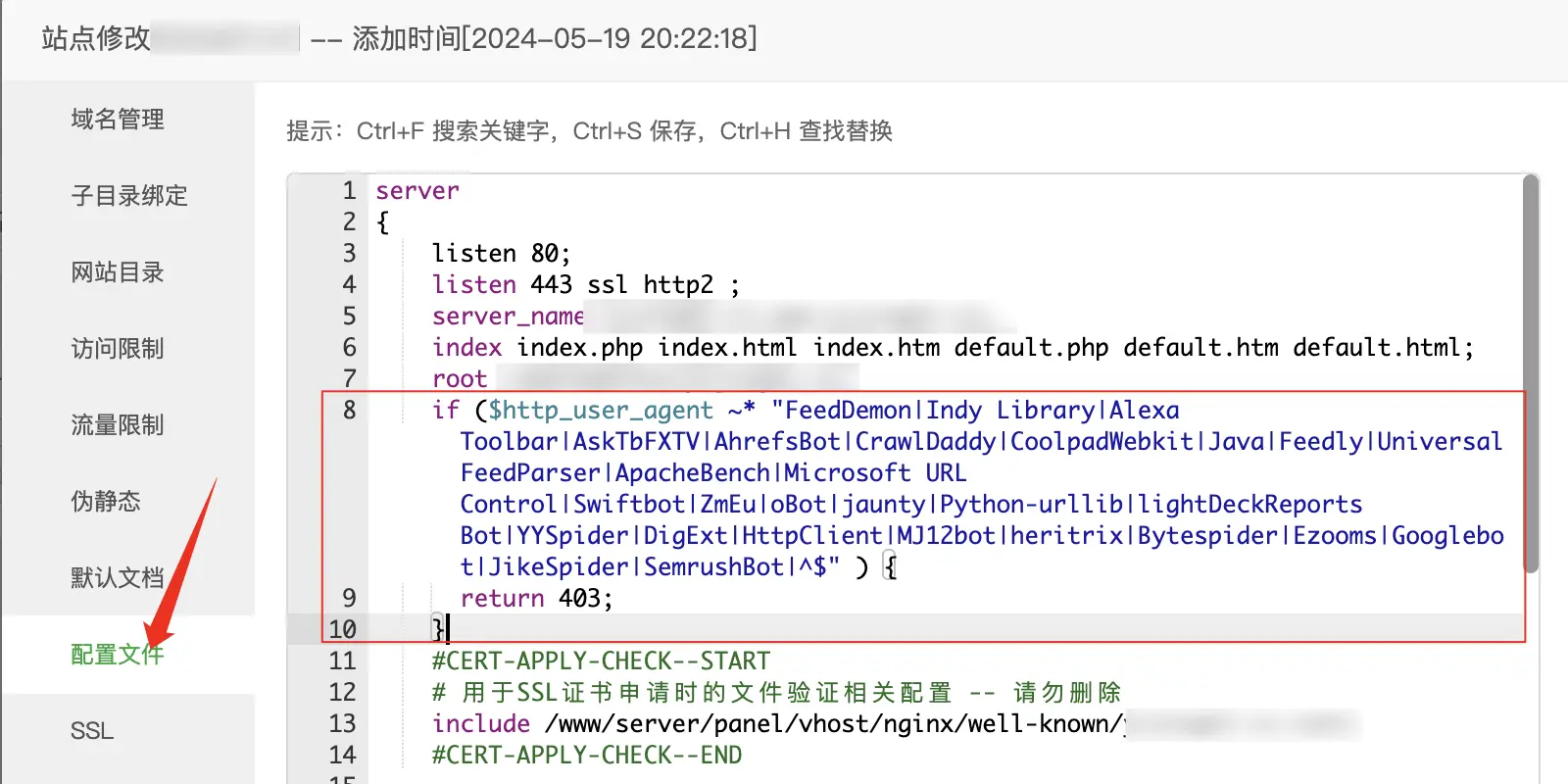
② 约8行处,添加如下代码并保存
if ($http_user_agent ~* "FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|Bytespider|Ezooms|Googlebot|JikeSpider|SemrushBot|^$" ) {
return 403;
}收录的UA
FeedDemon 内容采集
BOT/0.1 (BOT for JCE) sql注入
CrawlDaddy sql注入
Java 内容采集
Jullo 内容采集
Feedly 内容采集
UniversalFeedParser 内容采集
ApacheBench cc攻击器
Swiftbot 无用爬虫
YandexBot 无用爬虫
AhrefsBot 无用爬虫
YisouSpider 无用爬虫(已被UC神马搜索收购,此蜘蛛可以放开!)
jikeSpider 无用爬虫
MJ12bot 无用爬虫
ZmEu phpmyadmin 漏洞扫描
WinHttp 采集cc攻击
EasouSpider 无用爬虫
HttpClient tcp攻击
Microsoft URL Control 扫描
YYSpider 无用爬虫
jaunty wordpress爆破扫描器
oBot 无用爬虫
Python-urllib 内容采集
Indy Library 扫描
FlightDeckReports Bot 无用爬虫
Linguee Bot 无用爬虫
代码中我屏蔽谷歌蜘蛛|Googlebot| ,同时也屏蔽了垃圾搜索引擎蜘蛛和目前大部分爬虫,后续可以查看网站日志,返回状态码为403就可以了。初次想要验证结果,可将百度蜘蛛|Baiduspider| 添加上,到百度搜索资源平台试着抓取诊断一下,基本上都是抓取失败的。
原创文章,作者:霍欣标,如若转载,请注明出处:https://www.bigengwu.cn/shu/59.html